Getting started with redcapfiller
Source:vignettes/articles/getting_started.Rmd
getting_started.RmdREDCap is an electronic data capture software that is widely used in the academic research community. It provides tools building and managing online surveys and databases. These tools allow a designer to create complex data collection instruments with rich data typing, validation rules, repeating data structures, and time-series data collection and present these in a data-collection project. Data collected using this REDCap Project must conform the rules in the project definition. REDCap Filler provides a testing and development service for REDCap users. It generates and loads synthetic test data into a REDCap project, using the project’s design to guide test data generation. This article provides a basic example using redcapfiller to populate a REDCap project.
TL;DR
Populating a project with 5 records of data is as simple as
library(redcapfiller)
generated_values <- get_project_values(redcap_uri, token)
purrr::walk(
generated_values,
~ REDCapR::redcap_write(
redcap_uri = redcap_uri,
token = token,
ds_to_write = .x
)
)Generating the data
The goal of redcapfiller is to generate a test dataset as complex as
the project design using nothing more than the project design. The only
required inputs are redcap_uri, the uri to a REDCap host’s
API interface, and token, an API token to a project on that
host.
library(redcapfiller)
generated_values <- get_project_values(redcap_uri, token)
#> 1 rows were read from REDCap in 0.1 seconds. The http status code was 200.
#> The data dictionary describing 20 fields was read from REDCap in 0.1 seconds. The http status code was 200.
#> 26 variable metadata records were read from REDCap in 0.1 seconds. The http status code was 200.
#> The data dictionary describing 20 fields was read from REDCap in 0.1 seconds. The http status code was 200.
#> 1 instrument metadata records were read from REDCap in 0.1 seconds. The http status code was 200.
#> 1 rows were read from REDCap in 0.1 seconds. The http status code was 200.
#> 0 data access groups were read from REDCap in 0.1 seconds. The http status code was 200.
#> 335 records and 1 columns were read from REDCap in 0.2 seconds. The http status code was 200.
#> Starting to read 335 records at 2025-07-09 10:38:00.078375.
#> Reading batch 1 of 4, with subjects 1 through 100 (ie, 100 unique subject records).
#> 100 records and 26 columns were read from REDCap in 0.2 seconds. The http status code was 200.
#> Reading batch 2 of 4, with subjects 101 through 200 (ie, 100 unique subject records).
#> 100 records and 26 columns were read from REDCap in 0.2 seconds. The http status code was 200.
#> Reading batch 3 of 4, with subjects 201 through 300 (ie, 100 unique subject records).
#> 100 records and 26 columns were read from REDCap in 0.2 seconds. The http status code was 200.
#> Reading batch 4 of 4, with subjects 301 through 335 (ie, 35 unique subject records).
#> 35 records and 26 columns were read from REDCap in 0.2 seconds. The http status code was 200.The object returned by get_project_values() is always a
list.
typeof(generated_values)
#> [1] "list"For classic projects, like this example, the list will always have
length of 1. This will make more sense when we run
get_project_values() against a longitudinal project.
length(generated_values)
#> [1] 1Each list element is a tibble with a filled-rectangle of data.
generated_values[[1]] |>
rmarkdown::paged_table()Don’t be distracted by the character data types on the numeric columns. They still conform to the project design.
Writing the data
Writing the synthetic data to REDCap requires you walk the list to
write each list element. This is easy with
purrr::walk()
purrr::walk(
generated_values,
~ REDCapR::redcap_write(
redcap_uri = redcap_uri,
token = token,
ds_to_write = .x
)
)
#> Starting to update 5 records to be written at 2025-07-09 10:38:03.445047.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 0.5 seconds.Longitudinal data
redcapfiller can handle longitudinal projects with any
number of forms, events, and form-event relationships. The code is
exactly the same as before, but the generated data is more complex. In
the our longitudinal example we are adding five records to a project
with this form-event matrix:
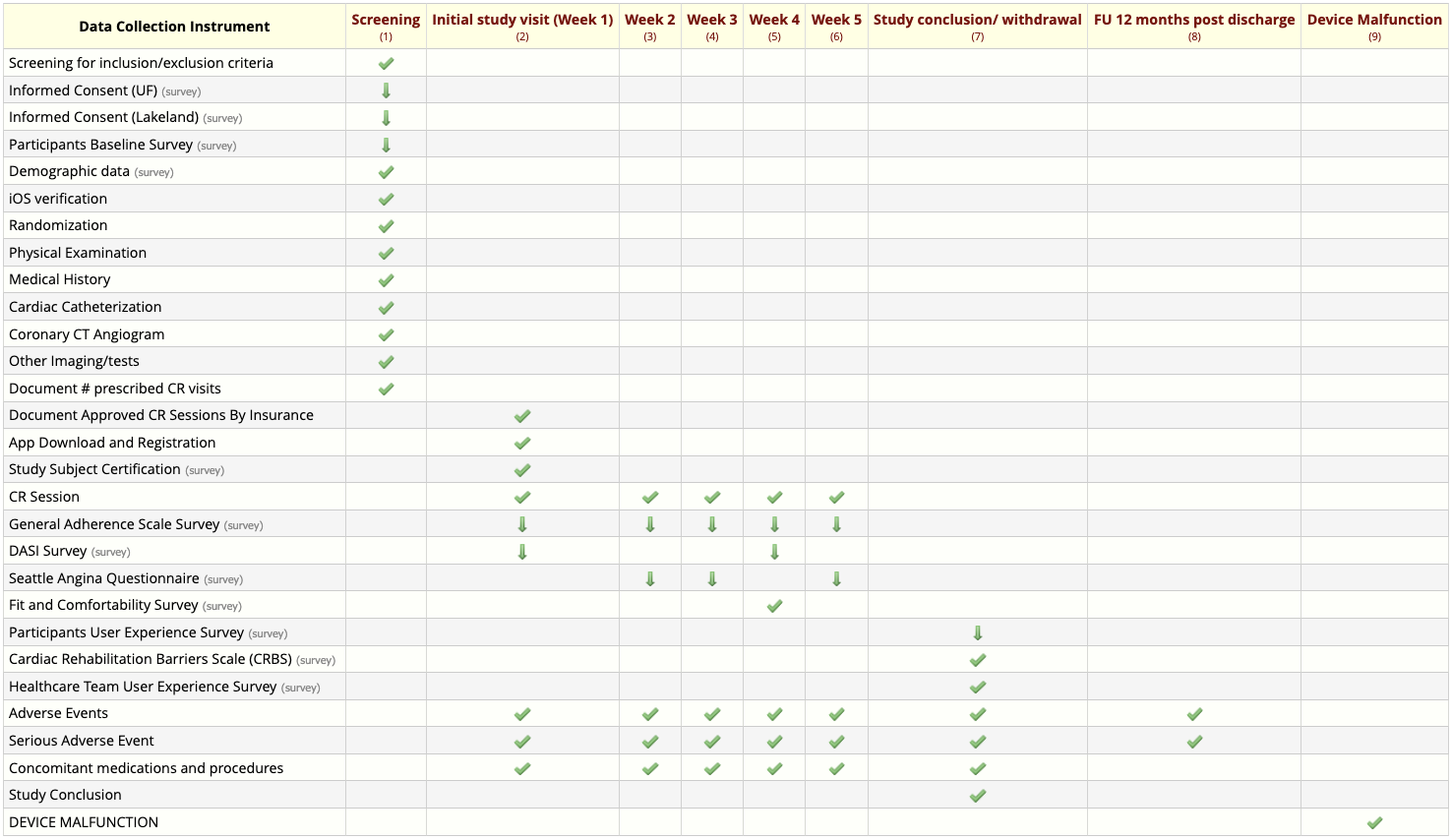
get_project_values() detects the longitudinal features
of the project and creates a list element for each of the nine
longitudinal events. Each element has data for the forms and fields on
that event.
library(redcapfiller)
generated_values <- get_project_values(redcap_uri, token)
length(generated_values)
#> [1] 9The write operation uses the same code, but this time there are nine write events of five records each.
purrr::walk(
generated_values,
~ REDCapR::redcap_write(
redcap_uri = redcap_uri,
token = token,
ds_to_write = .x
)
)
#> Starting to update 5 records to be written at 2025-07-09 10:38:11.825083.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.5 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:13.830707.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.3 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:15.609931.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.2 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:17.343435.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.1 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:18.982538.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.1 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:20.588319.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.3 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:22.411334.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 1.0 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:23.928275.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 0.5 seconds.
#> Starting to update 5 records to be written at 2025-07-09 10:38:24.912486.
#> Writing batch 1 of 1, with indices 1 through 5.
#> 5 records were written to REDCap in 0.5 seconds.get_project_values() parameters
You can specify the number of records you want to generate.
library(redcapfiller)
generated_values <- get_project_values(
redcap_uri,
token,
number_of_records_to_populate = 10
)
generated_values[[1]] |>
nrow()
#> [1] 10In a longitudinal project, you can specify a vector of events you want to fill.
library(redcapfiller)
generated_values <- get_project_values(
redcap_uri,
token,
events = c("screening_arm_1", "week_2_arm_1")
)
length(generated_values)
#> [1] 2