REDCap Custodian includes its own job logging facility. The system is designed to log each job run to a single row in a MYSQL database. With as little a four lines of code, you can log job success or failure along with a message. e.g.,
library(redcapcustodian)
library(dotenv)
init_etl("my_useful_script", log_db_drv = duckdb::duckdb())
# do some stuff ...
log_job_success("It worked!")The code in above would produce a row in the logging database like that shown in below.
| job_duration | job_summary_data | level | log_date | project | instance | script_name | script_run_time |
|---|---|---|---|---|---|---|---|
| 0.198606 | It worked! | SUCCESS | 2026-06-22 20:28:47 | my_useful_script | 2026-06-22 20:28:47 |
Behind the scenes
That’s a tiny script, but a lot is happening. Let’s decode what’s going on in those few lines.
library(dotenv)
REDCap Custodian uses the dotenv package to read files
of name-value pairs into the environment of the script. By default it
reads .env from the current directory. To make logging work
correctly, that .env file will need a stanza like this:
LOG_DB_NAME=rcc_log
LOG_DB_HOST=127.0.0.1
LOG_DB_USER=rcc_log
LOG_DB_PASSWORD=password
LOG_DB_PORT=9000The “LOG_DB_*” strings are the environment variable names
redcapcustodian uses to locate the MySQL DB where it stores
the logging data. You need to use these names and the values need to
point at a MySQL table on a MySQL server.
init_etl()
init_etl("my_useful_script") sets the
script_name env variable to “my_useful_script”, sets the
script_run_time env variable to the current date and time,
and it verifies the connection to the database described by the
“LOG_DB_*” environment variables. If the database is there,
init_etl() quietly exits. If the database is not there you
will see
Failed jobs
When jobs fail, you might want to log that condition, for that, call
log_job_failure(). As with log_job_success(),
you can provide a message to give more detail about what went wrong.
log_job_failure("input dataframe was empty")More detailed messages
Logging “It worked!” or “input dataframe was empty” is fine, but often, you want to provide more detail about a job’s activities. Chances are you have some useful facts in R objects already. It is a simple matter to assemble those objects into a list, convert the list object into a text string with using JSON libraries, and use that string as the job’s message. If you wanted to report some updates you made to the ‘iris’ database, you might log it like this:
init_etl("iris_updater")
# Do some stuff
# ...
iris_updates <- iris |> dplyr::sample_n(3) |> select(Sepal.Length, Species)
# ...
# success!
log_message <- dplyr::lst(iris_updates)
log_job_success(jsonlite::toJSON(log_message))The summary value can contain any number of JSON-encoded
objects. That said, plan them carefully. Ask what questions you will
want to answer later after a job has run. The package authors have found
the most common questions posed are “Why did this value change?”, “Who
(or what) set the value?”, and “When did this change?” Store as little
information as is needed to answer those questions succinctly. If you
provide lots of different objects, it might make for a pile of log data
to sift through later. We’ve found we can usually meet these needs by
including minimal dataframes of the data written by the job.
If you have multiple jobs writing to the same dataset, consider the value of self-consistency across those jobs. If every update operation of the invoice table is logged in an object named invoice_updates, you can more easily search across those jobs.
Reading back log data
Reading back the log data presents a few challenges. When you are answering the “Who? What? When? Why?” questions you often have to search across multiple log events to find the job run that made the change. You can filter the log data to the time frame or jobs of interest, but you will still have to search multiple job summaries to find the one that made the change you care about.
If you encoded the job summary data with JSON, you’ll need to decode
it, but jsonlite::fromJSON is not vectorized. You’ll have
to iterate over the log records. Also, you’ll want to unnest the job
summary objects returned by jsonlite::fromJSON. REDCap
Custodian provides the function
unnest_job_summary_data_json_object() to help with these
operations. e.g.,
log_conn <- get_package_scope_var("log_con")
log_data <-
dplyr::tbl(log_conn, "rcc_job_log") |>
dplyr::filter(script_name == "iris_updater") |>
dplyr::collect() |>
dplyr::slice_tail(n = 3)
unnest_job_summary_data_json_object(log_data) |>
unnest(cols = "iris_updates") |>
kbl() |>
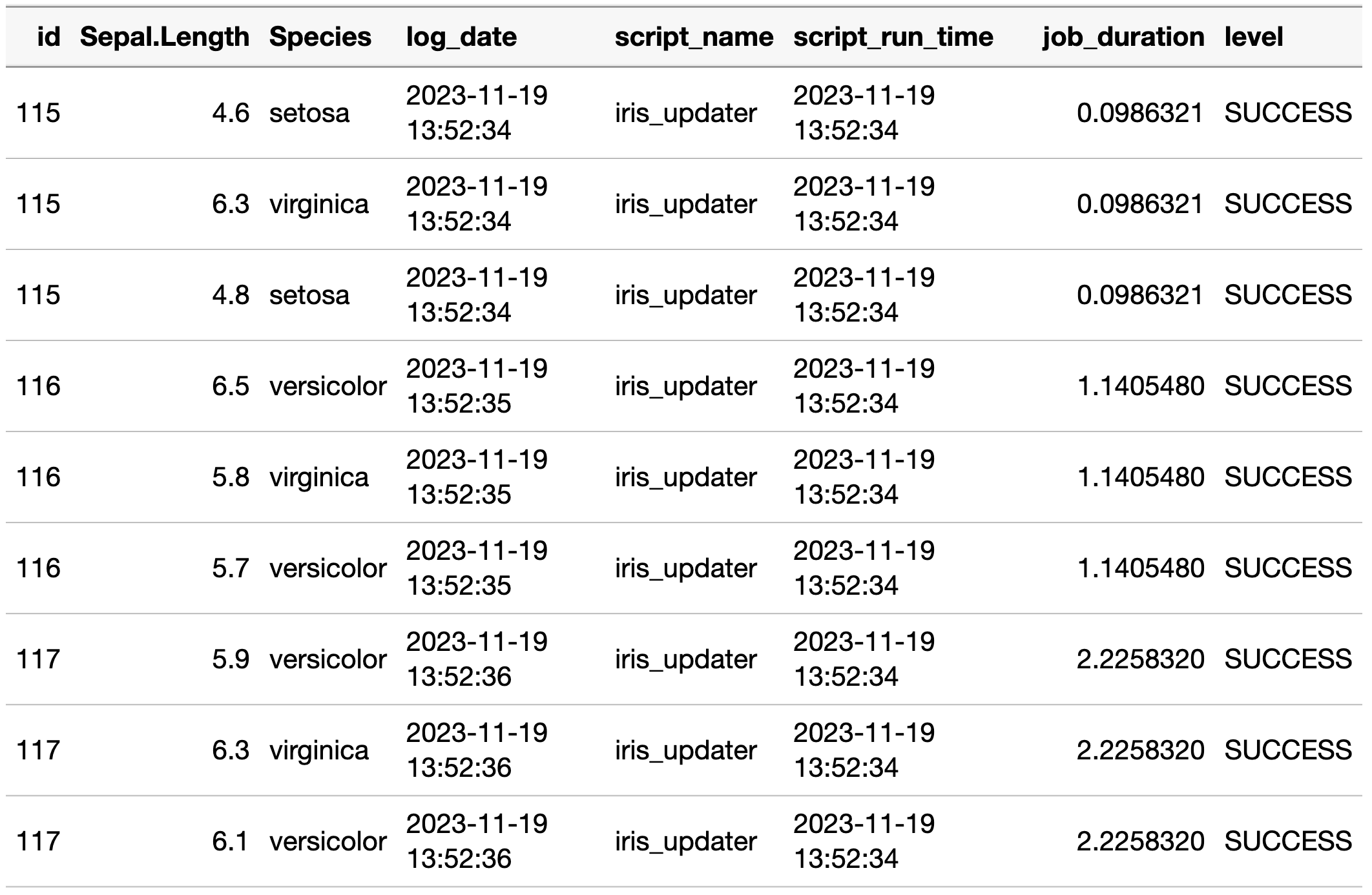
kable_styling()The output from unnest_job_summary_data_json_object,
once unnested, would look like: